8 Neighbours
8.1 Intuition
It is all starting to come together. It is now time to build the first prediction model in this book. \[ \text{Input} \longrightarrow \text{Model} \longrightarrow \text{Predictions} \]
A Machine Learning model learns the relationship between inputs and outputs to generate predictions on new inputs. For the first time in this book, this chapter will explore how these models learn.
Using the example of tumour diagnosis:
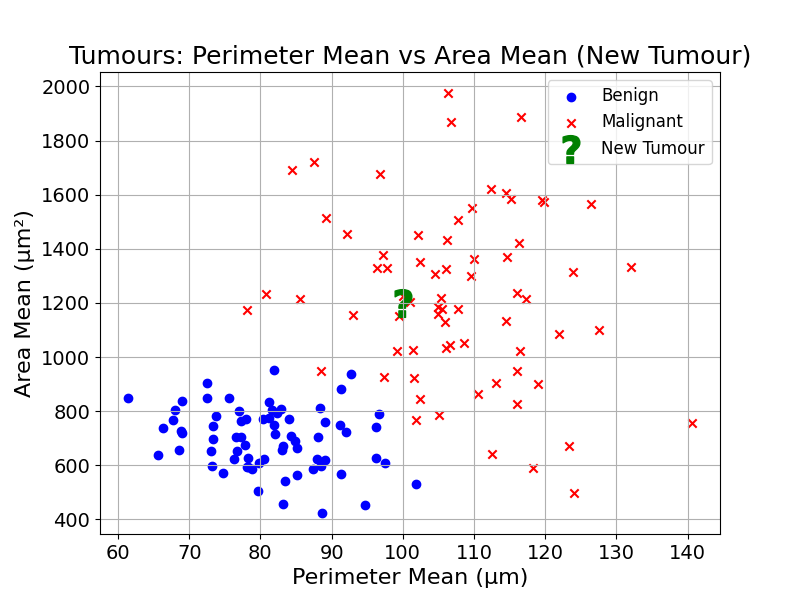
We want to predict the diagnosis of the observation labelled with a question mark (?). How could this be done using distance?
A good start would be to get the new observation’s closest neighbours. This can be done by calculating the distance between the new observation and the existing observations, and picking the ones with shortest distances.
Using your intuition, how would you classify this new observation?
What did our intuition rely on to make this judgement? When I came up with a prediction, I looked at the observation’s neighbours and applied a majority vote.
8.2 Algorithm
How can we build this intuition into a program, an algorithm?
The goal is to craft a list of rules that could be executed by a computer. Such a list could look like this:
- Find the 5 closest neighbours of the observation
- Count the number of neighbours per class
- The new observation’s predicted label is the class that has the highest number of neighbours
In Machine Learning, this model is referred to as K-Nearest Neighbours or KNN. \(K\) is the number of neighbours considered (here 5).
This model acts as a map from feature values to a prediction. Using the algorithm described above, any tumour observation can be assigned to a diagnosis. This map can be visualised by applying this majority vote to every point and colouring it by its diagnosis:
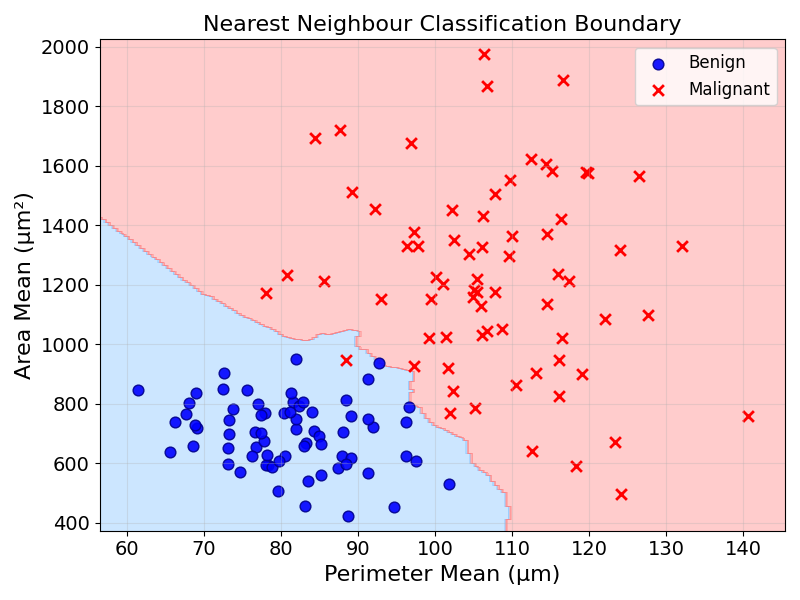
8.3 Adding some nuance
This is all very exciting. But let’s consider the following example from a patient’s perspective. Let’s imagine we have to predict the diagnosis of the following tumours:
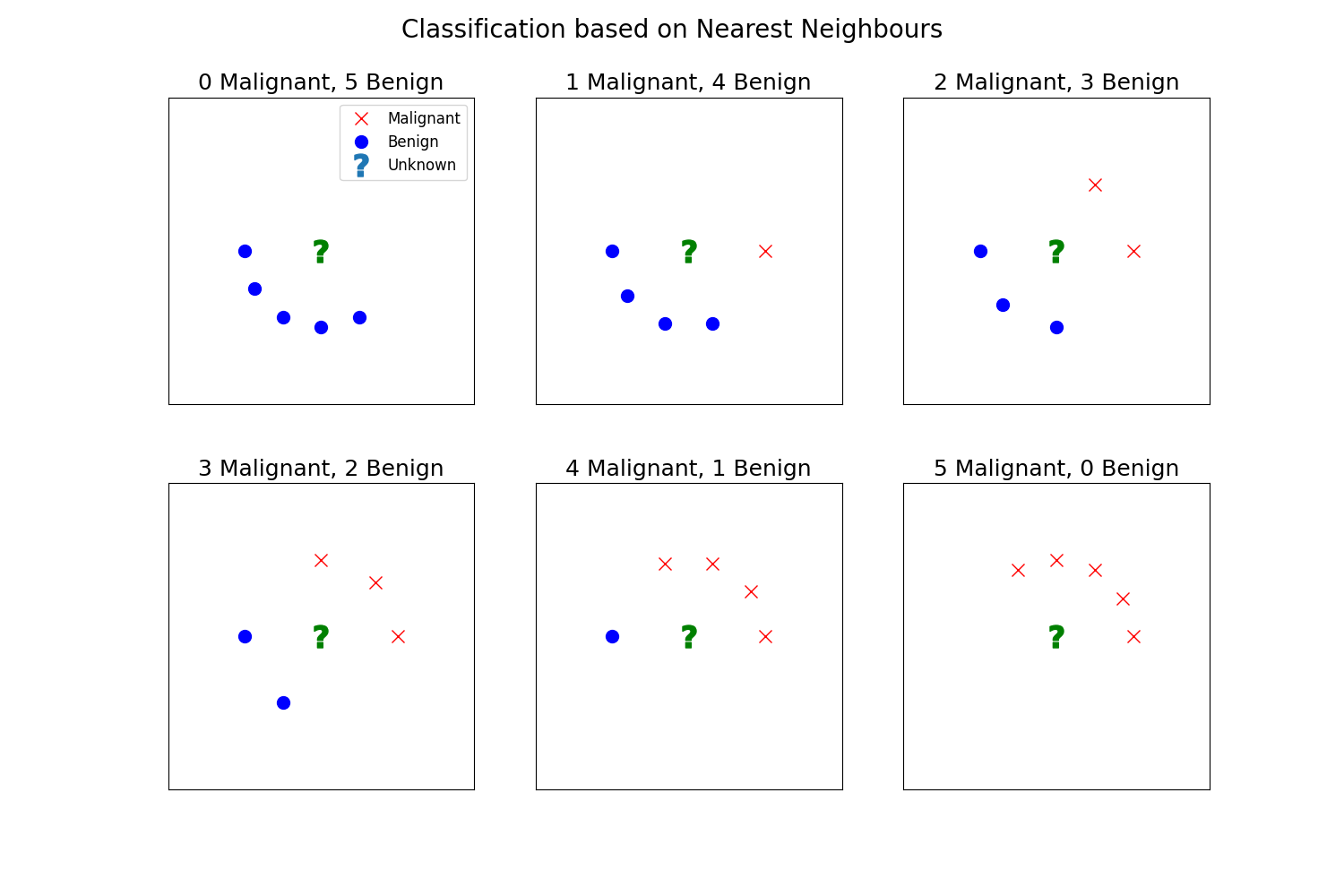
There, a simple majority vote would mean that the observation with 2 malignant neighbours could be classified as “benign”. As a patient, I would prefer to have a second opinion there.
As 2 out of the 5 neighbours of this observation are malignant, we are less sure that this tumour is benign. Could the model prediction reflect this uncertainty?
One way to do this would be, instead of taking the winner of a majority vote, we could estimate the probability of a tumour to be malignant.
The probability assigns a degree of belief to an event, between 0 and 1. 1 being the probability of an event that happens in all cases, and 0 the probability of an impossible event. For example, the probability of rolling a 4 on a fair six-sided die is \(1/6 \approx 0.167\). The probability of getting heads on a fair coin is \(1/2 = 0.5\).
Before computing the predicted probability of malignancy, we could start with intuition. If the 5 neighbours of the observation are malignant, the model should be 100% sure that the tumour is malignant. Conversely, if none of its 5 neighbours is malignant, the model would assign a probability of 0% to malignancy.
So far so good. But what about 3 and 2, or 1 and 4? By calculating the average, we could come up with a predicted probability.
If 3 neighbours are malignant and 2 are benign, we could compute the probability of malignancy with the expression:
\[ \text{Probability} = \frac{3}{3+2} = \frac{3}{5} = 0.6 = 60\% \]
Exercise 8.1 Calculate the probability of malignancy if four out of five neighbours are malignant. Show that it is \(80\%\)
By using this approach, the model can output more nuanced predictions that reflect the uncertainty in the training data.
This approach can be used to revise the map visualised in the previous section. Instead of being coloured by the predicted label, it is coloured by the predicted probability of malignancy (\(1\) malignant, \(0\) benign).
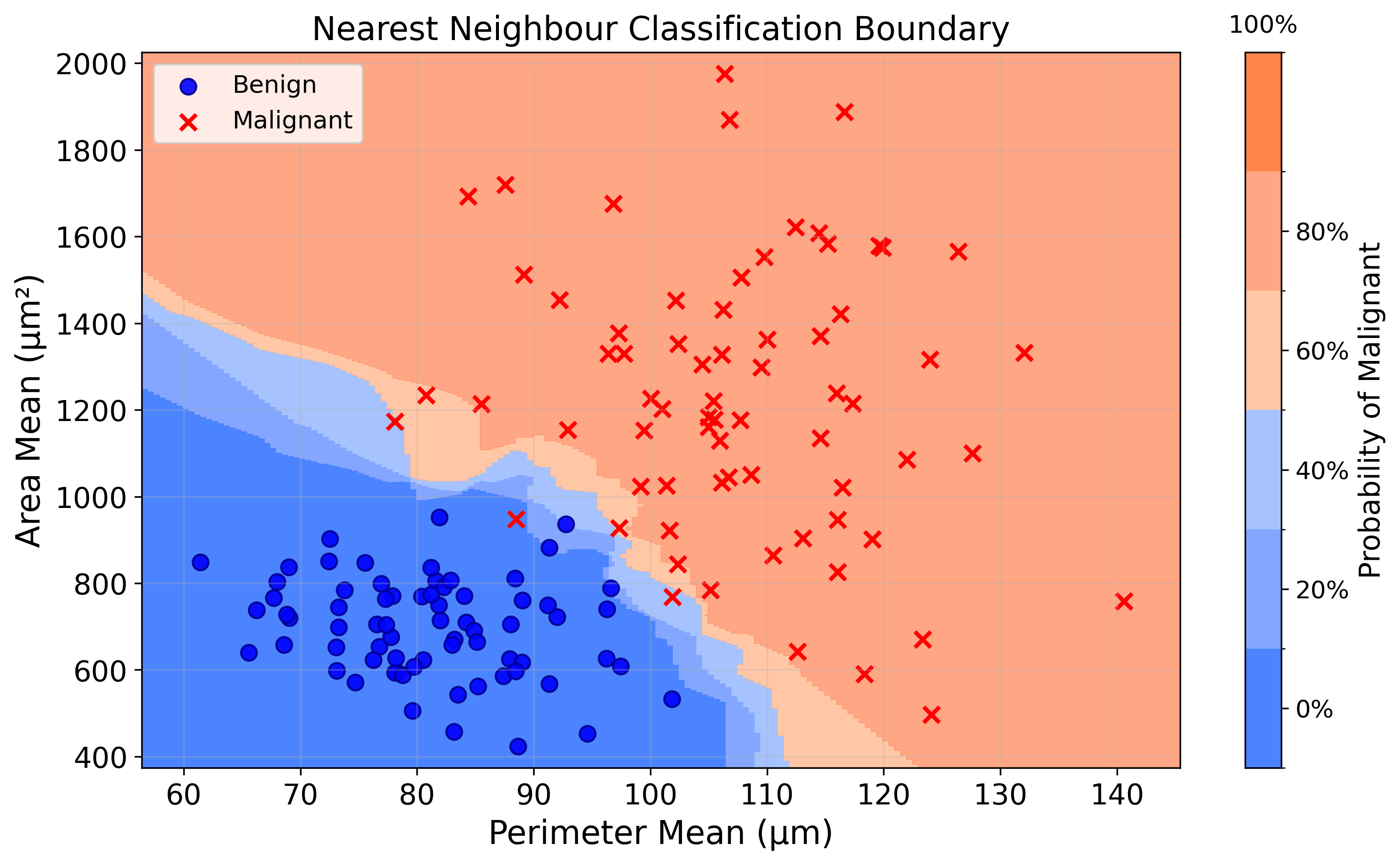
8.4 From classification to regression
The above section only showed the application of KNN to a classification problem, predicting the diagnosis of a suspicious mass.
Could the same model be used for a regression problem (predicting a continuous quantity)?
To do so, let’s turn to the problem of property pricing. When selling a property, customers need to know how much their property is worth. This can be used as a basis to compute the listing price, price for which the property is first listed. It is also in the buyer’s interest to have a very good estimation of the value of a property before agreeing to the transaction.
As explained in the Defining Prediction chapter, this pricing can be done with:
- Intuition: From experience, real estate agents have an understanding of the property market in their area of specialisation. They could “know” how much a property would be worth
- Rule-based Systems: Property analysts could build models that price properties based on their characteristics. A simple rule working surprisingly well is: average price per square meter * surface area of the property
Can we use the Nearest Neighbour model to learn from historical data and generate new price predictions for unseen data? Another leading question. Yes.
For simplicity, let’s use the following features: number of rooms and distance from centre (\(km\)).
The training data looks like this:
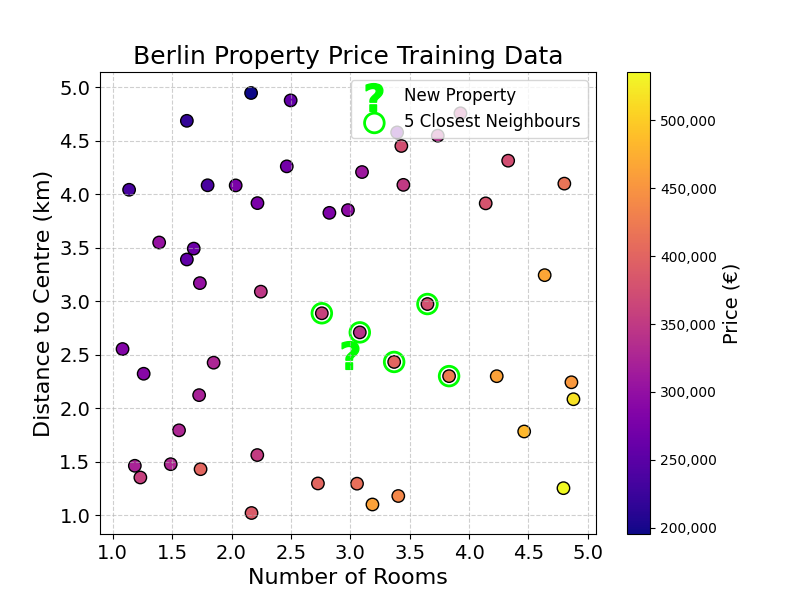
Each dot represents a property, coloured by its price. The question mark (\(?\)) is the new property we want to price.
How would you predict the new observation’s price? You could start by selecting its 5 closest neighbours. The five closest neighbours are highlighted on the chart and shown in the table below:
| Number of Rooms | Distance to Centre (km) | Price (k€) |
|---|---|---|
| 3 | 2.7 | 341 |
| 3 | 2.4 | 401 |
| 3 | 2.9 | 358 |
| 4 | 3.0 | 377 |
| 4 | 2.3 | 425 |
Now, how could we generate a single prediction from this list?
The simplest approach would be to compute an average of all the neighbouring prices and use this as the prediction:
\[\text{Predicted Price} = \frac{451 + 467 + 457 + 468 + 436}{5} = \frac{2279}{5} = 456\]
That is it, we have our predictions! This process should remind you of probability predictions.
Using this method, we could also compute a map of property prices over the two features: number of rooms and distance from centre.
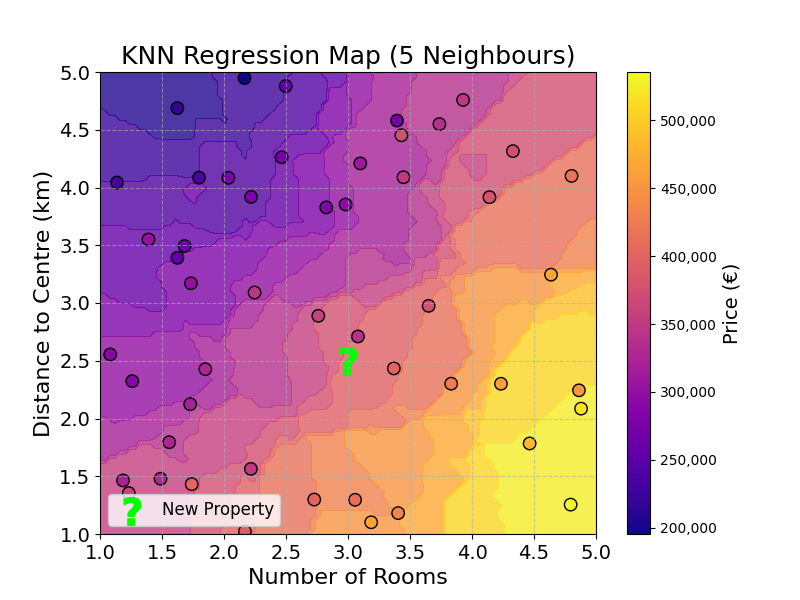
The map shows that there is a positive relationship between number of rooms and price, and a negative relationship between distance to centre and price. The most expensive properties are both central and have a high number of rooms. The (simple) model built allows us to map any given combination of number of rooms and distance to centre to a price.
8.5 Final Thoughts
KNN is the first of the Machine Learning models studied in this book. It learns the relationship between input features and a target, using distance calculations and average over neighbours. Can you think of a way you could use KNN to predict something in your everyday life?
We have our first model, but how good is it? We will explore this in the next chapter.
8.6 Practice Exercise
Exercise 8.2 Suppose you are building a model to detect fraudulent transactions. You use two features, both measured on a 0–100 scale:
- Transaction Amount ($) (0–100)
- Customer Age (years) (0–100)
You have the following 10 transactions in your training data:
| Transaction Amount | Customer Age | Fraudulent? |
|---|---|---|
| 95 | 22 | Yes |
| 90 | 25 | Yes |
| 92 | 23 | Yes |
| 97 | 21 | Yes |
| 93 | 24 | Yes |
| 94 | 23 | No |
| 20 | 80 | No |
| 25 | 78 | No |
| 18 | 82 | No |
| 23 | 77 | No |
A new transaction occurs with an amount of 93 and customer age 23.
Question:
1. Calculate the distance from each observation to the new transaction.
2. Identify the 5 nearest neighbours and their labels.
3. What is the predicted probability that the new transaction is fraudulent?
8.7 Solutions
Solution 8.1. Exercise 8.1
\[ \text{Probability} = \frac{4}{4+1} = \frac{4}{5} = 0.8 = 80\% \]
Solution 8.2. Exercise 8.2
The distance between two observations is calculated as:
\[ \text{Distance(A,B)} = \sqrt{(b_1 - a_1)^2 + (b_2 - a_2)^2} \]
where \(A (a_1, a_2)\) are the features of the training observation, and \(B (b_1, b_2)\) are the features of the new transaction (93, 23).
Let’s compute the distance for each observation using:
\[\text{Distance} = \sqrt{(\text{Amount} - 93)^2 + (\text{Age} - 23)^2}\]
| Amount | Age | Fraud? | Distance |
|---|---|---|---|
| 95 | 22 | Yes | 2.24 |
| 90 | 25 | Yes | 3.61 |
| 92 | 23 | Yes | 1.00 |
| 97 | 21 | Yes | 4.47 |
| 93 | 24 | Yes | 1.00 |
| 94 | 23 | No | 1.00 |
| 20 | 80 | No | 92.60 |
| 25 | 78 | No | 87.46 |
| 18 | 82 | No | 95.43 |
| 23 | 77 | No | 88.41 |
Sorted by distance (nearest first):
| ID | Distance | Fraudulent? |
|---|---|---|
| 3 | 1.00 | Yes |
| 5 | 1.00 | Yes |
| 6 | 1.00 | No |
| 1 | 2.24 | Yes |
| 2 | 3.61 | Yes |
The 5 nearest neighbours are:
- 4 fraudulent: ID 3, 5, 1, 2
- 1 non-fraudulent: ID 6
Predicted probability of fraud:
\[ P(\text{Fraud}) = \frac{4}{5} = 0.8 = 80\% \]