2 First Prediction with Machine Learning
With Machine Learning, we can generate predictions based on historical data. These predictions can solve problems in the real world.
Imagine this scenario: you are an early-career doctor and you receive a biopsy report. The lab lists two measurements from the cell nuclei of a suspicious mass — an average perimeter of 100 µm and an average area of 1200 µm². From just those two numbers: is the mass more likely benign (non-cancerous) or malignant (cancerous)?
If that vocabulary sounds unfamiliar, don’t worry — the question is straightforward: can we predict the diagnosis of this tumour from two measurements?
2.1 A visual approach
At first it might feel impossible. But suppose we have a database of many tumours, each labelled benign or malignant. A natural first step is to plot those examples using the two measurements from the report: perimeter and area. Each point on the chart would carry a label.
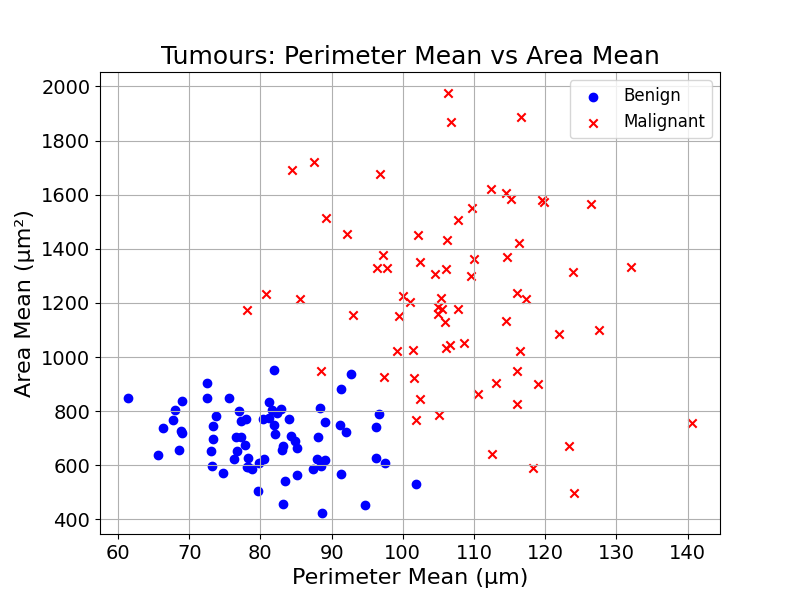
We could then plot the new observation on the same chart. We label it with a question mark as its diagnosis is still unknown.
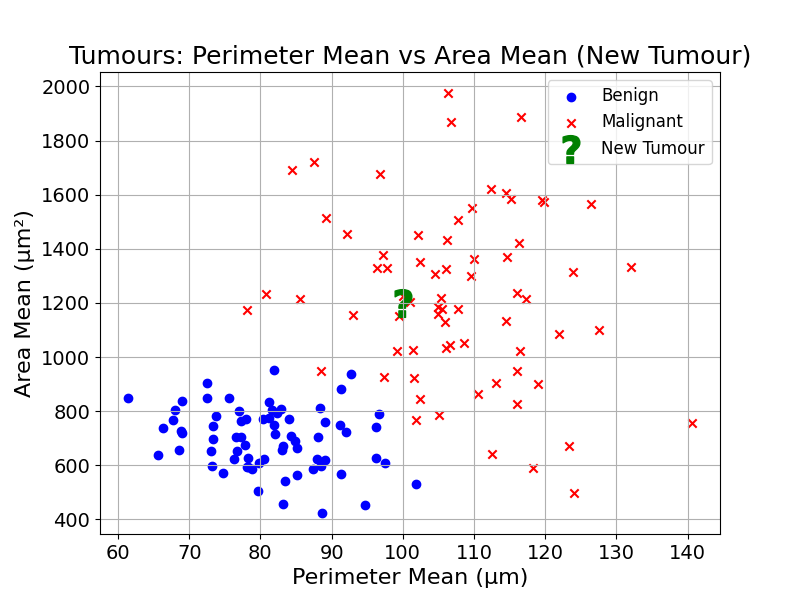
Would you now feel comfortable making an educated guess?
Look carefully: most of the unknown point’s nearest neighbours are malignant. From the data’s perspective, the most reasonable guess is that the tumour is malignant. That is not a certainty, it is a probabilistic judgement based on the available examples.
2.2 From intuition to algorithms
How could computers do the same? Computers do not (yet) have eyes, or an understanding of distance and closeness.
A prediction algorithm would need to find an observation’s closest neighbours. To do so, it would need to measure the distance between this observation and others, and pick the ones with the shortest distance.
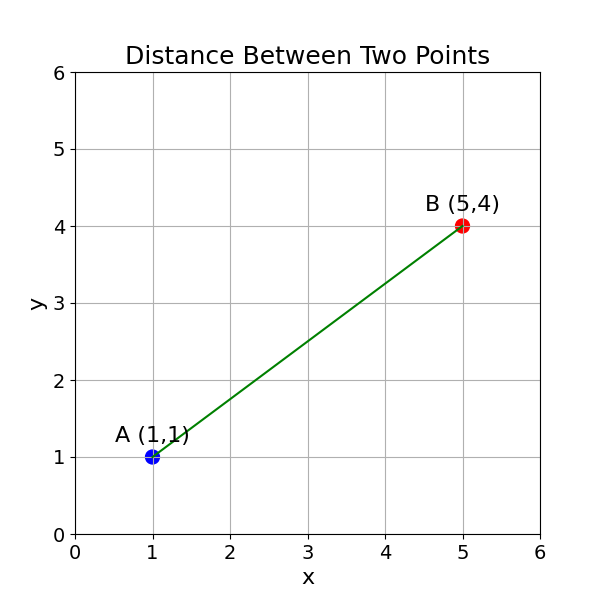
These distance calculations will be studied later. As a brain teaser, how would you calculate the distance between point A and B on this figure?
Hint: the Pythagorean theorem should be useful
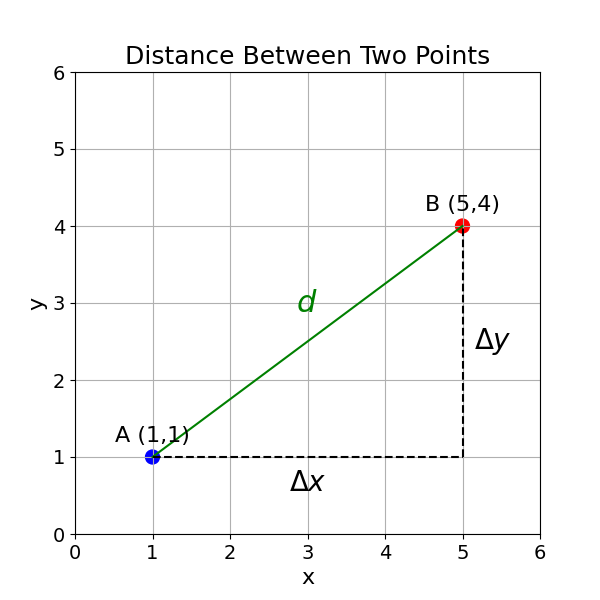
To find the distance between point A (1,1) and point B (5,4) using the Pythagorean theorem, we can consider these points as two vertices of a right-angled triangle.
The horizontal distance (\(\Delta x\)) between the points is: \[ \Delta x = x_2 - x_1 = 5 - 1 = 4 \]
The vertical distance (\(\Delta y\)) between the points is: \[ \Delta y = y_2 - y_1 = 4 - 1 = 3 \]
According to the Pythagorean theorem, the square of the hypotenuse (the distance \(d\) between points A and B) is equal to the sum of the squares of the other two sides (\(\Delta x\) and \(\Delta y\)): \[ d^2 = (\Delta x)^2 + (\Delta y)^2 \]
Substituting the values: \[\begin{aligned} d^2 &= (4)^2 + (3)^2 \\ d^2 &= 16 + 9 \\ d^2 &= 25 \end{aligned} \]
To find \(d\), we take the square root of both sides: \[\begin{aligned} d &= \sqrt{25} = 5 \\ \end{aligned} \]
The distance between point A (1,1) and point B (5,4) is 5.
With the list of closest neighbours, how would you make a prediction? Before coming up with an answer, think of how you would classify the following examples:
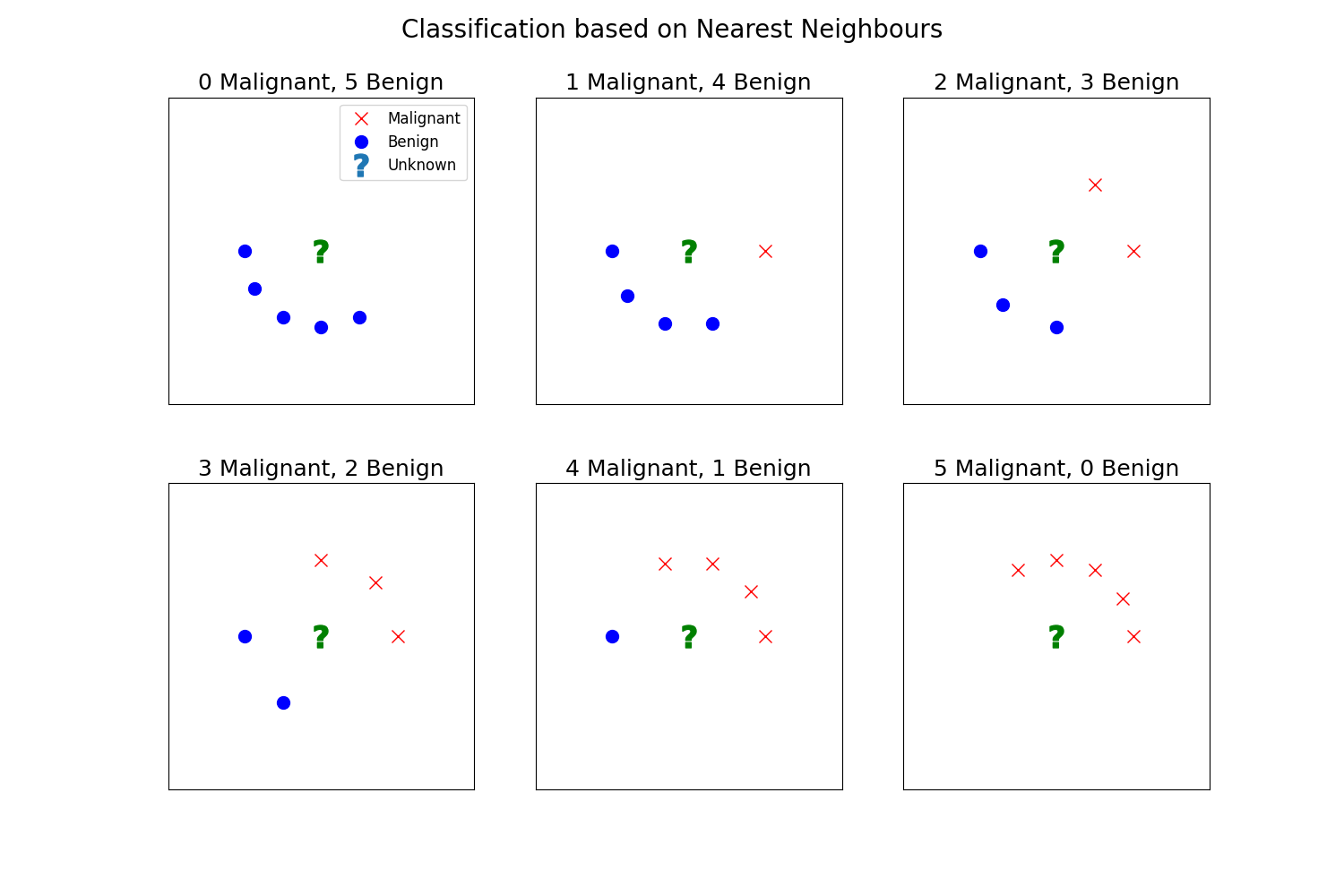
As you may have figured out, a simple majority vote should do. To generate predictions, count the number of neighbours belonging to each diagnosis, and assign the diagnosis with the highest number of neighbours.
That is it! We have our first model that can generate predictions about the world based on historical observations. This method could generate a diagnosis for any observation based on the value of the two measurements of its cell nuclei: average area and average perimeter.
This is only our first step into the fascinating world of Machine Learning. ML models can map any input, such as the above measurements, to any output, like tumour diagnosis.
Ready? Let’s get started.